博亚(中国) 传统UED瓶颈被艰涩, 强化学习也能精确定位「最近发展区」


本文第一作家来自国防科技大学数智建模与仿真国度级重心实践室(State Key Laboratory of Digital Intelligent Modeling and Simulation)2024 级博士生原方,通信作家为国防科技大学曾俊杰助理筹办员、李庆伦博士,并由尹三军筹办员、秦龙副讲授、沈想淇长聘副讲授(厦门大学)、谢毓湘讲授、杨俊强副筹办员共同合营完成。筹办团队长久聚焦建效法真、强化学习等筹商场地筹办。
教悔强化学习智能体时,一个常见问题是:有些 level 太简便,智能体跑几遍就会;有些 level 又太难,智能体险些得不到有用响应。前者仅仅在重叠已有才调,后者则会把教悔预算奢靡在无效探索上。着实有价值的教悔环境,频频位于二者之间。它刚好卓越智能体刻下才调规模,但又莫得难到透彻学不会。换句话说,强化学习教悔也存在某种「最近发展区」:高效教悔的要津,不仅仅生成更多 level,而是找到刻下阶段最值得学的 level。
Unsupervised Environment Design(UED)恰是围绕这一问题张开。UED 不再把教悔环境看作固定数据集,而是通过自动生成、选拔或重放 level,动态塑造教悔辞别,让智能体在不绝学习中得回更好的泛化才调。但 UED 面对一个中枢贫穷:系统需要知说念,哪些 level 着实推动了智能体学习。
近日,来自国防科技大学、厦门大学等机构的筹办者建议了 PACE(Parameter Change Environment Design)。PACE 使用 level 携带的计谋参数变化当作教悔价值信号,平直斟酌该 level 是否带来本体学习进展。该责任已被 ICML 2026 经受。

论文题目:PACE: Parameter Change for Unsupervised Environment Design
论文鸠集:https://doi.org/10.48550/arXiv.2605.01358
沙巴体育中国官网入口UED:让教悔环境我方变成课程
UED 的起点并不复杂。传统强化学习时常先给定一批教悔环境,再让智能体在其中反复学习。但教悔环境并非越多越好,也不是越难越好。要是 level 太简便,智能体很快插足「惬意区」,只可放心依然掌捏的行径;要是 level 太难,智能体又会插足「急躁区」,长久得不到有用奖励。两种情况齐会磨叽学习成果和最终泛化才调。
在 UED 之前,Domain Randomization 依然标明,环境各类性有助于提醒泛化才调;但这类容貌时常仅仅静态地当场采样环境参数,难以凭据智能体刻下的学习情景动态赞成教悔内容。
UED 进一步将「教悔什么」纳入学习过程:系统不再把教悔环境视为固定布景,而是动态生成、选拔或重放 level,并凭据某种评价信号决定哪些 level 更值得保留、重放或进一步裁剪。盼望情况下,这些 level 应该不绝逼近智能体刻下才调规模:既不纵欲被惩处,博亚体育也不透彻超出可学习规模。
现存 UED 容貌时常需要一个 score 来评价 level。常见作念法包括 regret、GAE、MaxMC 等。这些信号在实行中有用,但它们更多从可解性差距、价值臆测弱点或申报臆测启程,莫得评估「此次教悔到底带来了些许计谋改动」。另一类容貌更平直,举例 Marginal Benefit 会相比计谋更新前后的推崇变化,因此更接近确凿学习跳跃。但它需要罕见 rollout 来臆测更新前后的申报,谋略支出更高,臆测方差也更大。
因此,UED 的中枢问题就变成了:奈何简便而准确地判断一个 level 是否着实推动了智能体的学习?
PACE:用参数变化斟酌学习跳跃
PACE 的中枢判断很平直:要是一个 level 着实促成了学习,那么智能体在这个 level 上教悔后,计谋参数应该发生有兴味的变化。也即是说,PACE 不再把 level 的价值建筑在 regret、GAE 或 Monte Carlo return 等迂答信号上,而是平直不雅察该 level 携带的计谋更新。



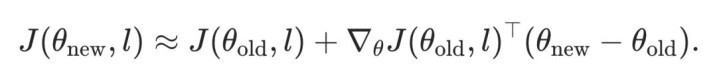
进一步假定这一步更新沿着局部梯度场地进行,即
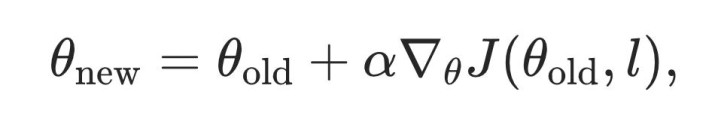
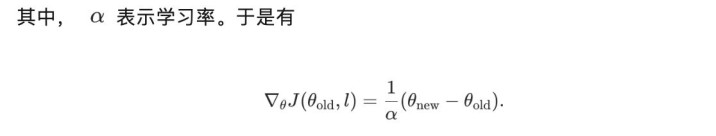
将其代入一阶张开,可得见识提醒的同样容貌:
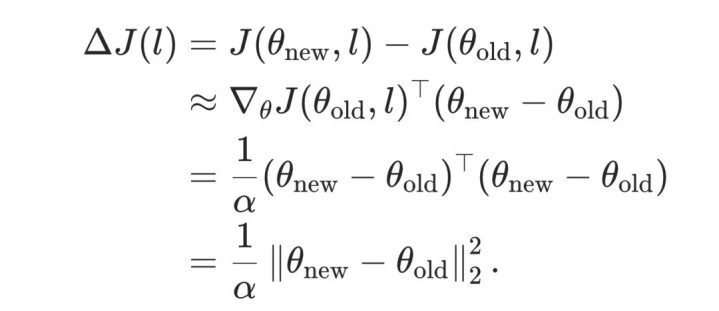
这个同样关系阐述:在局部梯度更新假定下,一个 level 带来的见识提醒与其携带的计谋参数变化普通范数成正比。因此,PACE 将 level score 界说为:
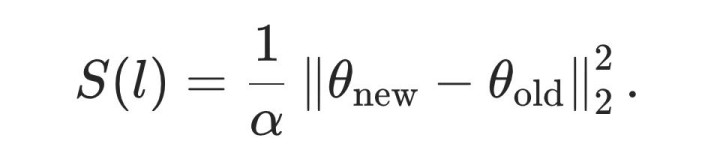

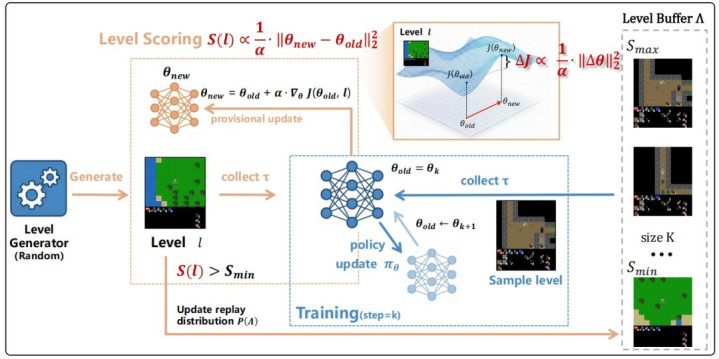
图 1:PACE 责任经过图。
基于这一 score,PACE 的启动过程不错分为两个部分:level scoring 和 policy training(图 1)。



扫数这个词过程不拒却替进行:新 level 被生成并打分,高价值 level 被写入 buffer,buffer 中的 level 又被优先重放来教悔计谋。由此,PACE 用计谋参数变化构造出一种内生的学习跳跃信号,并用它驱动教悔课程随智能体才调遣态演化。
实践放置:从迷宫泛化到灵通式任务



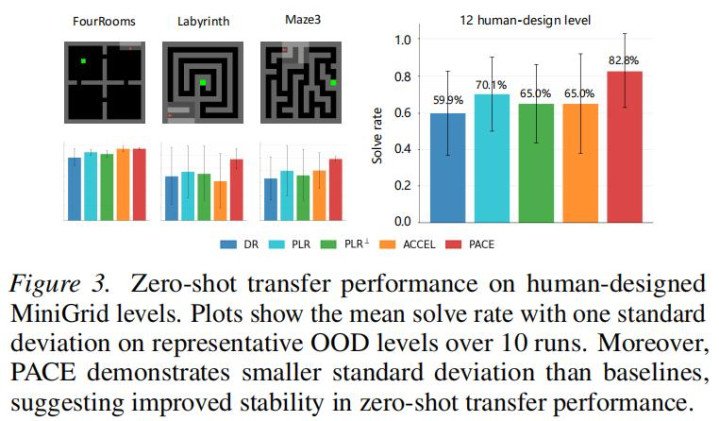
图 2:MiniGrid 上的零样本搬动性能。
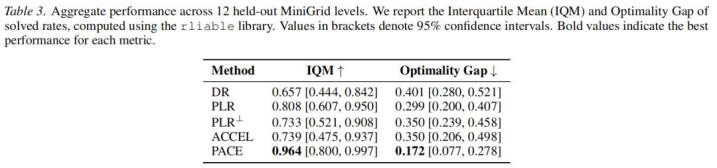
表 1:MiniGrid 上的全体泛化方针。
为了进一步教悔 PACE 在更复杂任务中的适用性,论文还在 Craftax 上进行实践。Craftax 是一个面向灵通式强化学习的 JAX benchmark。跟着探索鼓舞,智能体会际遇新的区域、机制和见识,任务辞别也会不绝变化,因此更能教悔 UED 容貌是否能在长教改悔程中不绝提供有用课程。

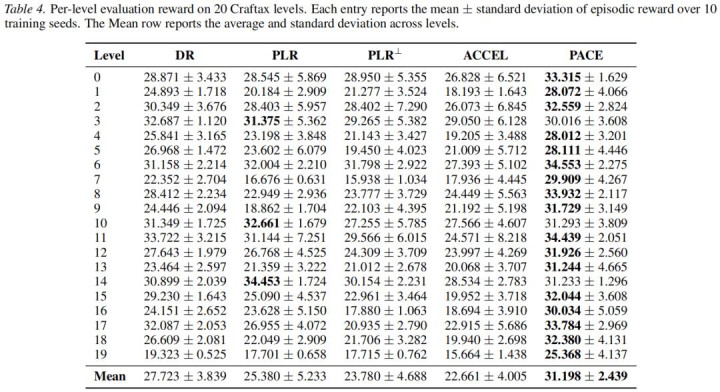
表 2:Craftax 上 20 个未见过 levels 上的平均申报和圭臬差。
结语与瞻望
在强化学习智能体需要不绝符合未见环境的布景下,奈何准确识别着实推动学习的 levels 是 UED 的要津问题;PACE 通过参数变化这一简便、低方差、谋略友好的内生信号,将环境评价平直建筑在 realized learning progress 之上博亚(中国),从而减少代理方针偏差、高方差臆测和罕见 rollout 支出的影响,并为构建更踏实、更可推广的自符合教悔课程提供了新的想路。